Azure Synapse Analytics üzerinde Lake Database Kullanımı ve Shared Metadata / Metastore Deneyimi
2023-01-04 Abdullah Kise
Azure Synapse Analytics, 2020 yılının sonlarına doğru tanıştığımız Lakehouse Veri Yönetim Mimarisinin uygulama sahası olan çok yönlü, yetenekli ve giderek daha fazla talep gören Microsoft'un göz bebeği bir Azure Veri&Analitik hizmetidir.
Bu hizmet daha önceki yazılarımızda da belirttiğimiz gibi bir çok farklı hizmetin yeteneklerini bir arada sunuyor. Özellikle Azure Storage, SQL (MPP), Spark (Distributed), Data Factory ve Power BI yetenekleri uçtan uca ve her ölçekteki analitik ihtiyaçlara cevap verebilecek seviyeye ulaşmış durumda. Data Explorer, Machine Learning, Cosmos DB ve hatta SQL Server 2022 ile çeşitli şekillerde uyumlu çalışması da göz kamaştırıcı nitelikte diyebilirim.
Azure Synapse Anaytics ile Enterprise BI, Stream Analytics, Machine Learning ve genel olarak Big Data odaklı ihtiyaçlarınızı etkili çözümler üretebilirsiniz.
Synapse Analytics ile ilgili anlatılacak çok şey var elbette, fakat biz bu yazımızda Shared Metadata veya Shared Metastore olarak ifade edilen bir özelliğe odaklanalım istiyorum.
Shared Metdata Özelliği Nedir?
Azure Synapse Analytics hizmeti ayağa kaldırıldığında ilk başta Serverless SQL Pool adı verilen MPP mimarisine sahip bir SQL engine görürüz. Serverless SQL Pool temel olarak üzerinde veri depolamayan fakat diskteki csv, parquet, json vs. tiplerindeki verileri OPENROWSET ve PolyBase engine sayesinde okuyup SQL dili ile veri dönüştürme imkanı veren ve genel olarak geçici işleri yürütmek için kullandığımız bir SQL enginedır.
Dilerseniz daha sonra Bir SQL veritabanında veri depolamak için Dedicated SQL Pool, Büyük Veri ihtiyaçlarına cevap üretmek için Spark Pool ve akan veri analizi için Data Explorer Pool açabilirsiniz.
Serverless SQL Pool üzerinde fiziksel tablo oluşturamasak da diskteki verileri tablo olarak görmemizi sağlayan CET (Create External Table) ve SELECT sonuçlarımızı diske yazdırıp tablo olarak sunan CETAS (Create External Table As Select) tablolarını oluşturulabiliyoruz.
Syanapse hizmetini ayağa kaldırdıktan sonra Synapse Studio üzerinden gerekli geliştirmeyi ve yönetimi yapmak mümkün. Synapse Studio üzerinde Data Bölümünden bir Serverless SQL Database oluşturabilirsiniz. Hemen ardından aşağıda görünen Workspace tabından bu veritabanına erişebilirsiniz. Dikkat ederseniz Tablo ile ilgili sadece External Tables klasorü yer alıyor. Yani CET ve CETAS tabloları burada listeleniyor.

Şimdi asıl konumuzla ilgili olan kısma gelelim: Yine aynı menüden bir 'Lake Database'i arayüz yardımıyla oluşturabilirsiniz.

İlk başta Database1 adında oluşuyor. Fakat daha sonra bu adın yanındaki gizli ".../ Open" ile açılan tasarım penceresinde, en sağda yer alan ayar buton ile Lake Database adını, konumunu ve varsayılan olarak veri depolama yöntemini belirtebilirsiniz. Değişikliklerin geçerli olması için Publish butonuna basmalısınız.

Oluşturduğumuz bu Lake Database tanımı Spark Veritabanı tanımı ile aynıdır (Hive uyumlu). Bu şekilde oluşturduğumuz tüm Lake Databaseler tüm Spark Poolları tarafından erişilebilir ve yönetilebilir, ek olarak Serverless SQL Pool tarafından da erişilebilir hale gelir.
Lake Database olarak isimlendirilen bu Spark veritabanı temsilinde oluşturduğumuz tablolar Spark Engine olmadan Serverless SQL Pool tarafından bakıldığında yeni bir veritabanı altında dbo scheması içerisinde External Table olarak listelenir ve içeriği okunabilir.
Designer penceresi veritabanı ve tablo oluşturmak için gerekli arayüzü bize sağlamaktadır. Fakat tablolara veri eklemek veya tabloların yapısını scriptlerle değiştirmek isterseniz Spark Pool açmanız gerekir.
Microsoft'un Shared Metadata olarak isimlendirdiği bu özellik ile oluşan, Hive uyumlu veritabanı temsili olan Lake Database metadatası ayrı bir katmanda depolanıyor ve bu metadata Serverless SQL Pool ve Spark Poollar arasında asenkron bir şekilde dağıtılıyor. Yani küçük bir gecikme ile Lake Database ve içindeki nesneler bahsettiğimiz poollardan erişilebilir hale geliyor.
Shared Metadata özelliği sadece tasarım ekranından oluşturulan Lake Databaselerin değil aynı zamanda Spark tarafından oluşturulmuş olan Hive veritabanlarının metadatasını da dağıtarak Serverless SQL Pool ve diğer Spark Poollar ile erişilebilmesini sağlıyor.
Merak edenler için güvenlik konusunda özetle şunu söyleyebiliriz; sorgu gönderen istemci ile ilgili güvenlik kuralları sorgu gönderdiği pooldan geçer ve dosya sistemi seviyesinde kontrol edilir.
Tablo Oluşturmak, Düzenlemek ve Sorgulamak
İlk aşamada Lake Database için ".../Open" ile açılan tasarım ekranında bir tablo oluşturalım. Diskteki bir dosyadan, template ile veya custom seçeneği ile istediğiniz bir tablo tasarımını yapabilirsiniz.
Custom seçeneği ile tablo oluşturalım istedik. Arayüz gayet açık. Tabloyu tıklayıp altındaki bölümden depolama seçeneklerini ve kolonları belirtebilirsiniz. Gerekli değişiklikleri yaptıktan sonra Publish ile bu değişiklikleri yayınlayalım.
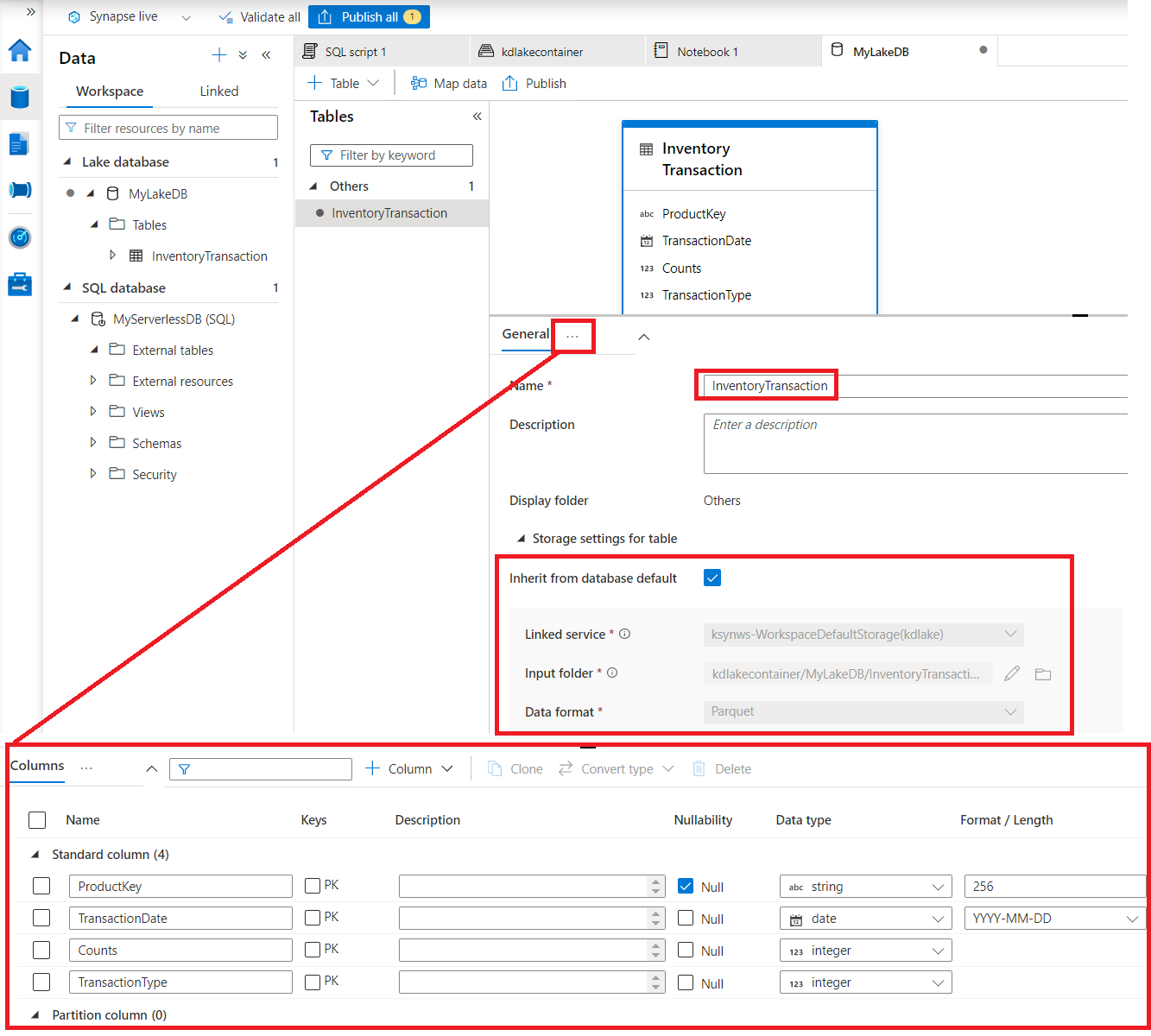
Oluşan tabloyu listelediğimizde yanındaki "... / New SQL Script" menusu ile sorgulayabilirsiniz. Yeniden hatırlatmak isterim tablomuz şuan boş, dilerseniz diskteki bir dosyadan tablo türetebilir, içeriğini hemen okuyabilirsiniz. Tabloya veri girişi yapmak için ve script ile düzenleyebilmek için Spark Pool oluşturmamız gerekli. Bu operasyonlar SQL Pool tarafından desteklenmiyor. Bu tabloları Serverless SQL Pool tarafında sadece SELECT ile okuyabiliyor.

Dikkat! Serverless SQL Pool bu tabloyu External Table olarak görüyor ve şuanda bu tablonun diskteki konumu henüz oluşturulmadı o yüzden custom tablo oluşturduğunuzda Spark tarafından veri girişi yapmazsanız aşağıdaki hatayı alırsınız.

Bu gayet normal bir durum. Şimdi tabloya Spark Pool tarafından veri girişi yapalım ve hatasız şekilde sorgulanmasını sağlayalım.
Ekran görüntülerinden de anlaşıldığı gibi Serverless SQL Pool tarafı Lake Databasei bir SQL veritabanı olarak görüyor. İçerisindeki tabloyu da dbo şeması alıntındaki External Tablo olarak yorumluyor. İşte bu Shared Metadatanın bize sunduğu bir nimet. Şimdi diğer nimete yani bu tabloyu Spark Pool tarafında nasıl yönetebileceğimize bir bakalım.
Spark Pool oluşturma adımlarına burada yer vermeyeceğim. Bir Apache Spark Pool'u Synapse Studio üzerinde Manage bölümünden kolayca oluşturabilirsiniz.
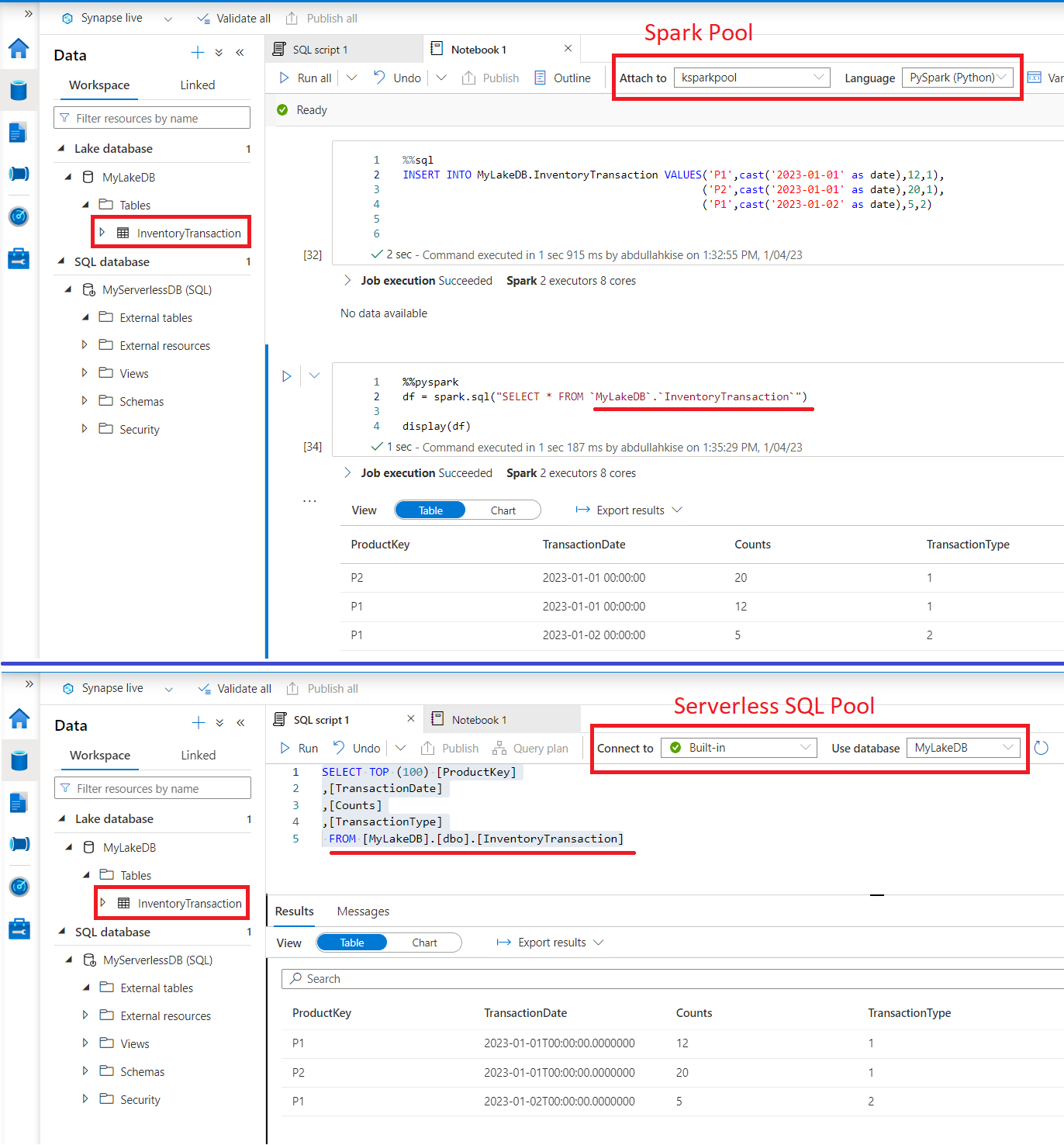
Tablo yanındaki ".../New Notebook" menusu ile bir notebook açalım ve Spark oturumu başlatalım.
Spark engine bağlı olan bu notebook üzerinde spark.sql fonksiyonu içerisinde HiveQL olarak bilinen bir tür SQL dilini kullanarak çalışabilirsiniz. Aşağıda sorgu sonucunu bir değişene DataFrame olarak attık ve show ile görüntüledik. Hücrenin üzerinde %%pyspark yazdığı için hücremiz Python dilini çalıştırıyor.

Şu an tablo içeriği boş. Biraz veri girişi yapalım. Yine HiveQL komutları kullanarak veri girişi yapabiliriz.
İlk hücrenin hemen altındaki "+ Code" butonunu tıklayıp yeni hücre ekler ve bu hücrenin en üst satırına %%sql yazarsanız spark.sql fonksiyonuna gerek kalmadan SQL komutlarını çalıştırabilirsiniz.
Kayıtları girdikten sonra tekrar sorguladığımızda hem Spark Pool tarafından hem de Serverless SQL Pool tarafından verilerin geldiğini görebiliriz. Bu arada farklı poolların tabloya erişirken farklı yollar kullandığını, yani FROM sonrasının farklı olduğunu gözden kaçırmayın.
Spark'ın Hive Kataloğuna kayıtlı veritabanlarını listelediğimizde arayüzden oluşturduğumuz Lake Databasei görebiliyoruz. Hemen sonrasında bu veritabanı içerisindeki tabloları listelediğimizde tablomuzun Spark tarafında External (Unmanaged) yani Hive'a register edilmiş fakat varsayılan hive lokasyonunda değil de bizim belirttiğimiz bir lokasyonda verilerinin depolandığını görebiliyoruz. External (Unmanaged) tablolarda metadata silinse de veriler diskten silinmez. Yani Spark ve SQL tarafındaki Extertnal Tablelar bu yönüyle birbirine benziyor.

Bu arada default isimli varsayılan bir Hive veritabanı da listelenmiş durumda. Yani Spark içerisinde bir CREATE TABLE scripti yazarsanız tablonuz doğrudan default veritabanı altına kaydolur. Tüm Lake Database tablolarına Serverless SQL Pool ve Diğer Spark Poollar üzerinden erişebilirsiniz.

Spark tarafında script ile oluşturulan Managed ve Unmanaged (External Table) tablolar Shared Metadata özelliği sayesinde Serverless SQL Pool tarafından okunabildiğini deneyimledik.
Eğer Spark tarafındaki bir veri kümesini diske doğrudan kaydetmiş iseniz bu durumda Hive'a register etmemişsiniz demektir. Bu veri kümeleri diskte dosya olarak durur fakat Spark veya Serverless SQL Pool tarafından tablo olarak görünmez. Yine de Serverless SQL Pool tarafından OPENROWSET ve PolyBase Engine sayesinde ya da Spark Pool tarafından spark.read. komutları ile diskteki bu verilere kolayca erişim sağlayabilirsiniz.
Özetle
Shared Metadata özelliği sayesinde Spark Veritabanları ve Manged/UnManged tabloları (şimdilik parquet ve csv depolama formatındakiler) SQL enginedaki temsilleri ile birlikte temel depolama düzeyinde korunur ve diğer poollar ile paylaşılır. Eğer bir Spark View oluşturmuş iseniz bunlar sadece Spark Poollar arasında paylaşılır. Spark tabloları Serverless SQL Pool tarafında External Table olarak temsil edilir fakat Spark Viewleri Serverless SQL Pool tarafında görünmez.
Dedicated SQL Pool ve Spark Pool arasında Scala dilinde yazılmış "spark.read.synapsesql" ve "spark.write.synapsesql" fonksiyonları ile doğal ve güçlü bir entegrasyon mevcut. Shared Metadata özelliği sayesinde Serverless SQL Pool ve Spark Pool arasında da başarılı ve kullanışlı bir entegrasyon deneyimleyebiliyoruz.